OCR Software

Do you want to make a digital format out of the hard copy of any document? If you do, OCR (abbreviation for “Optical Character Recognition”) technology is what you need.
Optical Character Recognition is widely used for digital replication. Most notably, OCR technology does more than simply read the fonts from scanned documents or digitally captured images – it can recognize line breaks in the document, split up columns, turn images into graphics, allow you to search the text by keyword, allow document editing, etc. The process is quite simple, easy to manage, and can take just a few seconds.
Paperless Concept Before OCR
Scanners and image-capturing devices were introduced with one goal in mind: to turn paper documents into electronic file formats that can be stored electronically.
Top 5 benefits of turning physical documentation into digital libraries are:
- Easier retrieval of data: The information is easily accessed via computer networks and/or internet by anyone with proper credentials. No more visits to the archive room and wasting time searching for the specific paper document.
- More space: A large amount of paper can take up lots of space, while the same amount of digital documents can fit on one hard drive and still leave room for more!
- Better management: Creating electronic folders and organizing digital files is infinitely more efficient than dealing with paper.
- Improved security: Digital documents can be easily backed-up on multiple drives. This makes them a lot more secure from natural disasters. Furthermore, administrators can encrypt the data and deny access to files with just a few clicks.
- Simplified viewing and sharing: Electronic documents can be viewed and shared an unlimited number of times without ever leaving the office desk.
With the introduction of scanning devices and the concept of a paperless office, businesses were able to save time and cut down on operating costs significantly.
Nevertheless, a need for technology that could turn those scanned, image-based documents into searchable and reusable files soon emerged in an attempt to make office work even more efficient. That’s when OCR stepped onto the stage and forever changed the way we deal with documents.
From Desk to Desktop: How OCR Works?
For humans, it makes no difference whether a document is a scanned, image-based file or any other digital file format. If we see letters, numbers, symbols, and images we understand them. But for computers, it’s not as straightforward.
Essentially, OCR technology helps computers break down a document’s structure into elements that can be deciphered. In an OCR program, what starts as a block of text separated from other formatting features, becomes a line of text, then words, and finally individual characters. Once the scanning is finished, the OCR algorithm replicates each character one by one and then reassembles the whole document with one important difference – the text is now extracted from the image and editable.
Though OCR technology has much improved since its beginnings, errors still occur. If the original document is handwritten, torn, smeared, old, coffee-stained or has any sort of marks that prevent easy content recognition, the machine will have difficulty “reading” and translating it into an accurate electronic version of the file.
However, advanced OCR programs are minimizing the conversion error occurrence rate with each version upgrade, and are now highly reliable and cost-effective. When it comes to scanned text and image documentation, OCR conversion software provides speed, flexibility, and control that are needed in every professional working environment.

Advantages of the OCR Technology
If you want to convert a document into an editable digital format, using OCR software is the best choice. It provides a fast and reliable alternative to typing manually. The Optical Character Recognition process can save both time and effort when developing a digital replica of the document.
Software with integrated OCR technology can convert a document into many different electronic formats, like Microsoft Word, Text (and Rich Text), Excel, and of course, it can also convert scanned PDF files.
All documents created through an OCR program are editable and allow you to modify the content as you see fit. If you compare the cost of OCR with the cost of manual data entry, OCR is a lot cheaper. It is already an indispensable part of most large companies’ office equipment and is valuable in industries that are heavily scanning documentation, such as legal departments and law offices, financial and insurance companies, government agencies, healthcare institutions, human resources departments, law and real estate firms, etc.
OCR has improved upon every aspect of the paperless concept, making documents searchable, editable, accessible, translatable… Document workflows have become less time and resource consuming, resulting in improved office productivity and decreased operating costs for companies.
OCR Conversions with Able2Extract Professional
As already mentioned, high accuracy OCR programs are able to read and convert volumes of scanned data in a very short span of time, creating editable documents that often contain no mistakes. Able2Extract Professional is an example of such software.
Able2Extract Professional is easy to use and can convert scanned PDFs and images containing text into the most popular electronic formats: MS Word, Excel, PowerPoint, HTML, OpenOffice, etc. It comes equipped with the most advanced Optical Character Recognition technology which is highly recommended to users with large amounts of hard copy documentation that need to be converted into an editable digital format.
How to OCR a PDF in Able2Extract
With Able2Extract, converting scanned, image-based files is as easy as converting native PDFs.
Step 1: Open the scanned PDF or image file containing text by clicking on the Open button in the main toolbar.
Step 2: Select what you want to convert using the options from the right-side panel or by drag-selecting relevant content (by default, the entire document is selected).
Step 3: Choose from the available conversion options under the Convert tab in the main toolbar and follow the prompts to finish your OCR conversion.
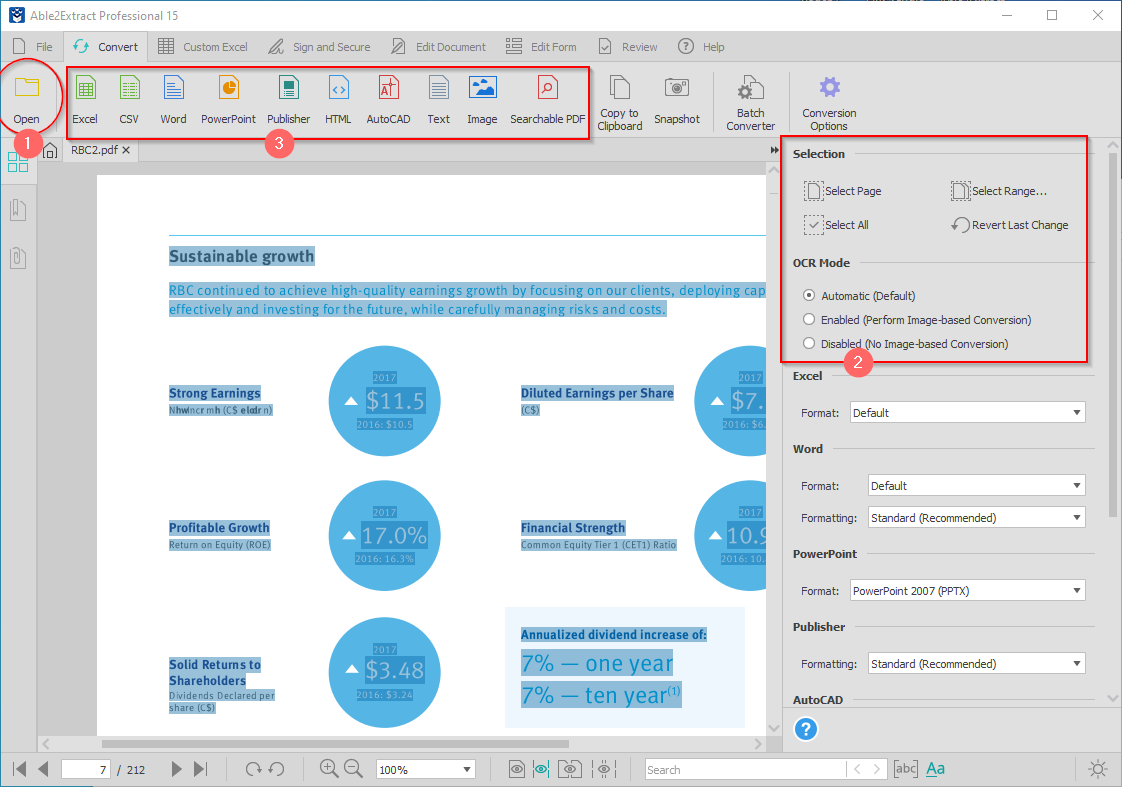
Able2Extract Professional will automatically recognize your PDF as scanned and run an OCR conversion by default, so you don’t need to bother with any unnecessary steps. Your content will be extracted accurately with little to no time invested nor wasted.
Take Able2Extract Professional OCR engine for a free test drive.