Scanned PDF FAQ

Are All PDF Documents the Same?
No, they are not. PDF documents can be created in a variety of ways. The two main methods you will commonly come across are PDFs created by an electronic source and PDFs created by scanning in paper documents. This results in a “native” PDF and a scanned PDF, respectively. This is important because the way a PDF is created has an impact on how you can interact with the PDF content later on.
What Is a Native PDF?
PDF documents created from an electronic source are known as “native” PDFs. Native PDFs are generated from digital file formats such as MS Word, or an MS Excel spreadsheet. Native PDF files have an internal structure that can be read and interpreted. These “generated” PDF documents already contain characters that have an electronic character designation. As such, conversion from such a PDF can rely on these electronic character designations and provide reliable output.
What Is a Scanned (Image) PDF?
PDF documents can also be created by scanning a paper document into an electronic format. This is done by using a scanner, or similar machine, that takes an image of a paper document and then stores this image as an electronic PDF file. A scanner does not recreate each character of every word when it creates this scanned image. Rather, it simply takes a “snapshot” of the paper document. This snapshot is then turned into a PDF document by software that is integrated with the scanner. The result is a “scanned” PDF document.
The content of a scanned PDF cannot be searched or edited. In order to search or edit a scanned PDF, OCR software is required to electronically identify each character on a page and then convert it into a useable format. Essentially, what it does is recognize and extract text from an image.
How Can I Tell Which Type of PDF I Have?
To distinguish which type of PDF file you have visually look at the text in your PDF document. Does the text look grainy? Are some letters broken? Does the page itself look like it was photocopied? If your answer to these questions is yes, then you have a scanned PDF.
If you answer to the questions above is no, then you have a native PDF.
What Is OCR (Optical Character Recognition)?
Optical Character Recognition (OCR) is a visual recognition process that turns printed or written text into an electronic character-based file. For instance, to convert a scanned PDF to Word or any other editable format, OCR software is required to analyze the “image” of each scanned in character and match it to an electronic character-based file.
A document that is scanned and converted into a PDF provides the basis for which character recognition software may interpret each character image on the PDF and assign it an electronic character-based file that can then be entered into an editable format, such as a Text, Word or Excel document.
What Are Some Common Issues for Converting Scanned PDF Files and Performing OCR?
There are issues that can affect the quality of the OCR output, such as poor image quality of the scanned document, a mixture of fonts used in the scanned documents, the italicized and underlining of fonts, all of which can blur the quality and shape of the individual characters. Because of this, it is much more difficult to ensure that the character that is “recognized” by the OCR software is the character on the scanned document.
How to Perform OCR and Convert Scanned PDF Documents?
There are a variety of PDF converter tools on the market today that can assist with OCR and scanned PDF conversion. If you’re looking to convert scanned PDFs to Word, Excel, PowerPoint, AutoCAD and other formats, a PDF suite like Able2Extract Professional can help. It contains advanced OCR technology which is used to accurately extract the information from scanned PDF files.
Here’s how to convert scanned PDF documents with Able2Extract Professional:
Step 1
In Able2Extract Professional, click on the Open icon on the main toolbar and open the scanned PDF that you want to convert.

*Note Able2Extract Professional automatically detects and performs OCR on scanned PDF documents.
Step 2 (Optional)
If you don’t want to convert the entire document, you can drag-select content you want to convert or use the selection options in the right-side panel.
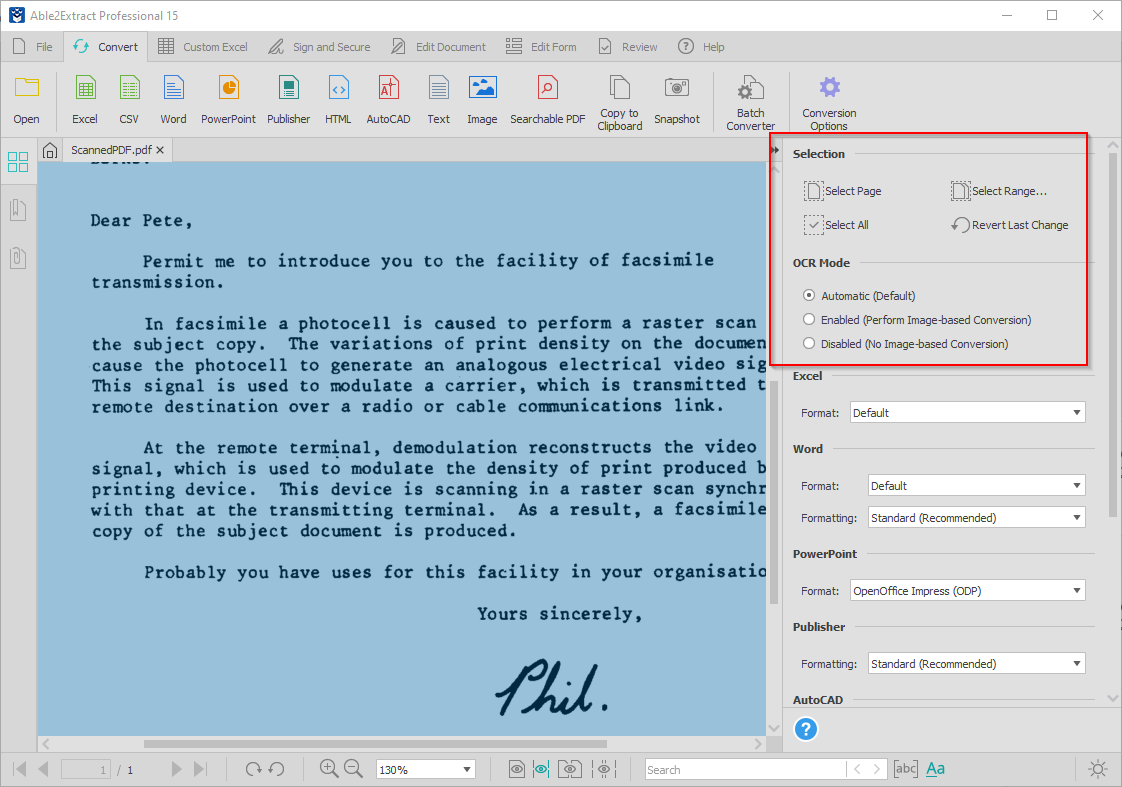
Step 3
Convert your scanned PDF to any of the supported formats (Word, Excel, AutoCAD, etc.) by clicking on the corresponding icon on the main toolbar.
