
Image credit: Zitona (Flickr.com)
The end of summer is near, and that means students will be heading back into the classroom in a couple of weeks. That being said, it’s time to sit down and think forward about the upcoming school year.
On top of the back-to-school shopping list and registration chaos, it’s a good time to start thinking about how technology will factor into your daily routine. We’re talking about the nitty-gritty routine spent on studying, researching, writing, and sitting in class.
So in case you haven’t thought about it yet, we’ve hammered out some basic tech advice on 6 things you should consider.
Map Out Personal Tech Support Resources
No matter how well you know your tech tools, there will always be a random issue you can’t fix in a hurry. Knowing where you can go for help is key. There’s only so much Google can do for you with 10 million results.
Do yourself a favour and get your resources mapped out ahead of time. Scout out, follow, and bookmark a good range of How-To sites, forums, and even basic support pages for your device.
Find Textbooks Online
When it comes to textbooks go digital wherever possible. Digital textbooks can be significantly cheaper than original hardcopy or photocopied versions, and you won’t have to lug around heavy volumes.
As a starting point, sites like Project Gutenberg offer a vast selection of books in a variety of formats. You can also take advantage of Google’s latest textbook rental and purchasing offer from Google Play Books. There’s also the iBooks app, whose iBookstore offers text books from notable publishers, such as McGraw-Hill and Pearson.
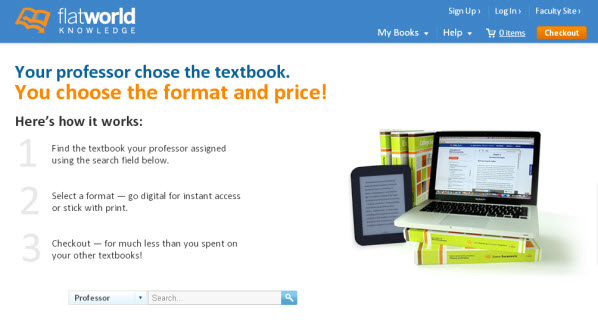
If those don’t pan out, you can check out FlatWorldKnowledge, an online catalog of textbooks where you can personalize textbook content according to your needs.
Shop Around For Free Software
You’re used to hearing of big name software applications like Microsoft Office and Adobe Photoshop that are above your price range. But you can just as easily get free software that offers the same functionality as other paid programs.
Search for open source software alternatives. There are a ton of free tools out there. You can also find apps for your device like productivity suites, note takers, and mobile converter apps. In addition, desktop suites like OpenOffice and LibreOffice are great alternatives to Microsoft Office you can get for free.
Organize Your Gadgets & Devices By Task

If you have more than one device, you should try getting them organized according to task. You may think this is counter-productive, but different sizes, apps and OSes can actually make working on multiple gadgets inconvenient.
Think about how you’ll be dealing with your school work this year. Will you be typing up your papers on a laptop in a coffee shop? Does research work better for you on a desktop? Or will you be on a tablet for on-the-go convenience? You get the idea.
Some devices are more practical than others for certain tasks. Figure out your studying habits and get a gadget strategy and workflow in place.
Adopt Different Study Habits For Online Classes
Some of your courses may be offered online or have an online bulletin board component set. Keep in mind that online learning environments have different dynamics and hence, need a different approach.
Tip? For starters, keep focused. It’s all too easy to get distracted with opened browsers, the comfort of your own room, and online networks. Moreover, we’re all used to scanning stuff online. So when it comes to in-depth reading, you’ll need to really shift gears once you log in. Remember that a lot of it is about independent learning.
Also, timeliness is a big factor that can possibly affect your grades. You want to be one of the first ones to submit a discussion response. Remember there are others who can possibly cover the same points you want to make. Don’t let them steal your thunder by posting it up first. In short, constantly scout out other minor adjustments you can make to your studying habits.
Always Have A Back Up Plan
All too often does a program crash on us in the middle of a paragraph, a USB gets lost, or we quickly close that 1,500 word paper without saving. But a few things can help prevent that.
Create a copy of your papers every few drafts to different storage media. Use cloud storage services like Dropbox to save a copy of your last draft.
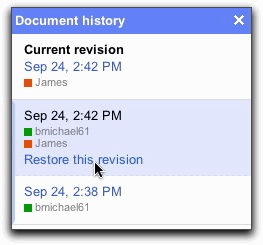
Or conversely, create your original copy online with Google Docs. It will save your changes automatically. In addition, it will create a back up of the file’s revision history. Let’s not forget that you can always send a draft to yourself as an attachment!
Once the year starts, a solid routine will be the only thing keeping you on top of things. So make sure you plan out your tech strategy well!
 Now, three months later, as its Ballot Resolution Meeting (BRM) draws near in February, OOXML’s standardization is still up in the air as its interoperability, the OOXML hot topic of the day, will be a major factor in the decision to approve it as such.
Now, three months later, as its Ballot Resolution Meeting (BRM) draws near in February, OOXML’s standardization is still up in the air as its interoperability, the OOXML hot topic of the day, will be a major factor in the decision to approve it as such.