Popular File Types
The complete PDF SDK that brings accurate PDF viewing, annotating, editing, creation, and generation functionalities to any applications and platforms.
Learn More
Office
Deliver accurate and reliable Office viewing, annotating, and conversion with a best-in-class Office SDK that eliminates your application’s reliance on external third-party or open-source libraries.
Learn More
CAD
Bring accurate, reliable and fast support for CAD and BIM formats to any application or workflow with a CAD SDK proven to handle the large and complex drawings used in today’s architecture, engineering, and construction workflows.
Learn More
DELIVER POWERFUL AND PEFORMANT SOLUTIONS THROUGH A SIMPLE-TO-USE SDK
Embed Apryse Server SDK to deliver scalable performance into your backend document processing and workflow applications
Get Started in Minutes
Find success quickly, with best-in-class documentation, support, and cookbooks that were built by developers, for developers. Sign up for a free trial, use our SDK in your language choice, and make your first API instantly.
Flexibility for any document need
Accommodate current future use cases with the most complete document SDK on the market, supporting all major platforms, 30+ file formats, and hundreds of unique features.
Keep Your Data, Yours
Built with security in mind, embed our powerful, reliable and secure SDK into your document application and workflows, free from third-party hosted services.
DOCUMENT GENERATION
Create new PDF documents programmatically, or merge your data source with Office and HTML templates to rapidly generate large numbers of highly personalized documents.


FILE CONVERSION
Embed high-fidelity document conversion from PDF to Office and Image formats, XPS, HTML, and the other way around, all free from third-party server dependencies.
ANNOTATIONS
Add any of the 35+ out-of-the-box annotations programmatically to your documents, including mark-ups and watermarks. You can also flatten annotations, fill forms, and add permission settings.

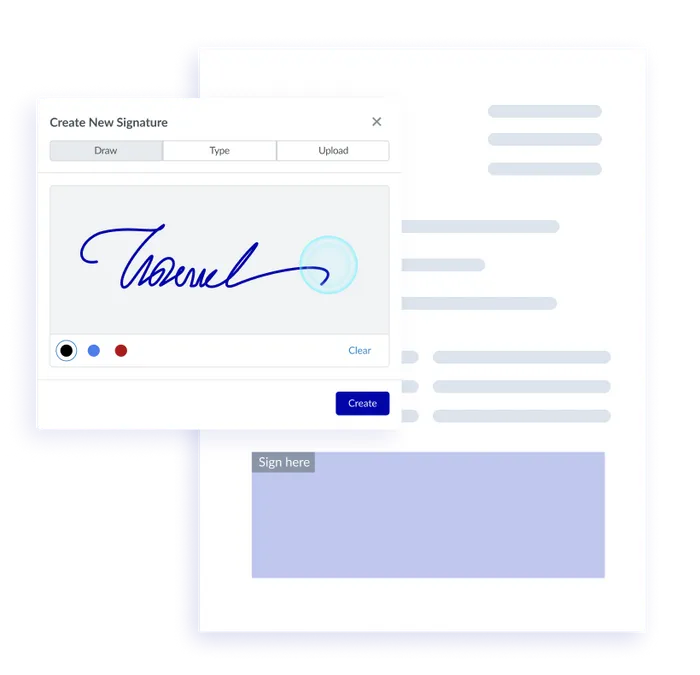
DIGITAL SIGNATURE WORKFLOWS
Add compliant signature fields, sign workflows, prompts, and styles to your documents. Multiply your productivity and sign any number of documents programmatically with saved signatures.
REDACTION
Securely redact confidential information programmatically from your documents. Search and redact ensures compliance with laws such as CPRA and GDPR by location and by irreversibly removing personally identifiable information from PDFs.